Content Marketing Intelligence
Your content team is producing. Your analytics team is reporting. Neither one knows which content is actually driving revenue or why.
Content marketing generates one of the most complex attribution problems in digital marketing.
A customer reads a blog post in January. Returns to read another in March. Watches a YouTube video in April. Clicks a paid ad in May. Purchases in June.
Which content piece drove the revenue? Last-click attribution credits the paid ad. First-click attribution credits the January blog post. Linear attribution distributes credit equally across all five touchpoints. None of these models are correct. All of them are arbitrary mathematical simplifications of a genuinely complex causal process.
The attribution problem is just the beginning.
Beyond attribution, content marketing has a saturation problem too many pieces competing for the same search intent, cannibalizing each other’s organic performance. It has a decay problem previously high-performing content drifting semantically away from current audience intent without any visible signal on standard analytics platforms. It has a fraud problem content being systematically scraped and republished, creating duplicate signals that dilute organic authority. And it has an engagement problem users arriving on content pages and leaving at specific structural points that standard bounce rate metrics cannot identify with sufficient precision to act on.
Content Marketing Intelligence applies NLP, unsupervised machine learning, survival analysis, and Markov Chain graph modeling to solve each of these problems with mathematical precision transforming content from an activity that is difficult to measure into a strategically optimized asset that generates verifiable, causally attributed revenue contribution.
The Problem With Standard Content Marketing Analytics
Standard content analytics operates on a small set of metrics that have remained largely unchanged for fifteen years:
Pageviews. Sessions. Time on page. Bounce rate. Scroll depth. Conversion rate. And if sophisticated assisted conversions in a multi-touch attribution report.
Every one of these metrics has a fundamental measurement problem:
Pageviews and sessions measure traffic volume not content quality, not audience relevance, not business impact.
Time on page is unreliable it cannot be measured for the last page in a session, and it conflates genuine reading engagement with an abandoned browser tab.
Bounce rate is a blunt instrument that cannot distinguish between a user who read every word and found exactly what they needed (high quality outcome) and a user who arrived and immediately left because the content was irrelevant (low quality outcome).
Scroll depth is a proxy for engagement that does not distinguish between a user who scrolled quickly to find a specific piece of information and one who read every line carefully.
Conversion rate attributes conversion to the landing page ignoring the multi-touchpoint content journey that preceded the conversion.
Assisted conversions in standard attribution reports use arbitrary credit allocation models that do not reflect the causal contribution of each content piece to the conversion outcome.
The result is a content marketing function that produces extensively but cannot prove rigorously which of what it produces creates business value making strategic content investment decisions based on intuition, industry benchmarks, and the subjective assessments of whoever has the most authority in the room.
Content Marketing Intelligence replaces intuition with mathematical evidence connecting content production to revenue generation through causal models that can withstand statistical scrutiny.
The Five Content Marketing Intelligence Solutions
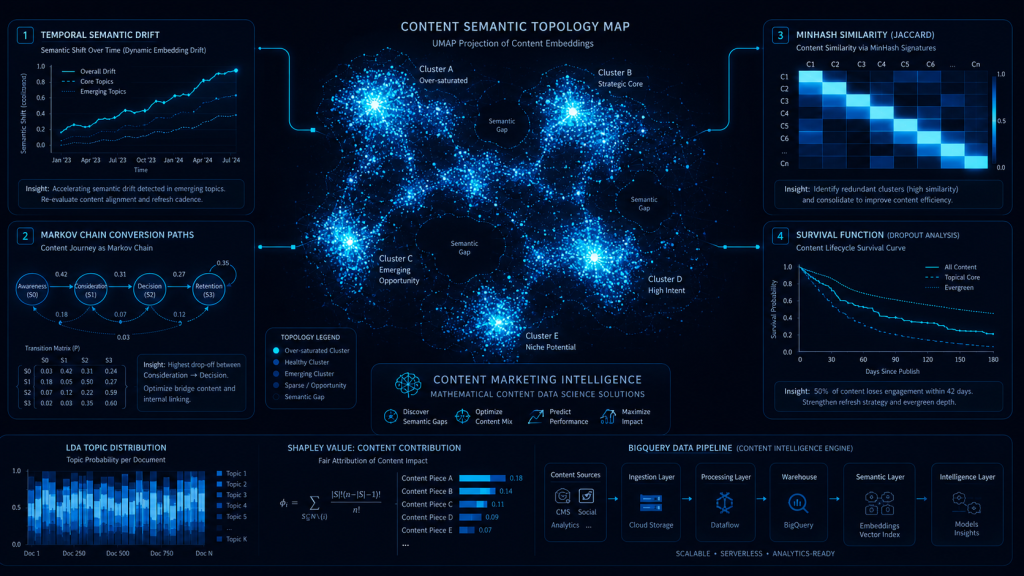
Solution 01 Topical Topology & Content Saturation Mapping
Powered by UMAP + HDBSCAN Density Clustering + Semantic Gap Analysis
The problem this solves:
Every content library has two simultaneous problems that standard keyword research and content auditing tools cannot detect with mathematical precision:
Over-saturation: Multiple content pieces competing for the same underlying search intent splitting organic authority, diluting click-through rates, and preventing any single piece from reaching its ranking potential. This problem is more severe than simple keyword cannibalization because it operates at the semantic intent level pieces targeting different keyword phrases can compete for the same underlying informational need in Google’s ranking model.
Under-coverage: Genuine audience questions and information needs that exist at scale within the target market but are not addressed by any existing content representing organic ranking opportunities that are being systematically missed because standard keyword research tools do not reveal demand that does not yet have significant search volume.
Both problems waste content production budget one by producing content that competes with itself, the other by producing content in areas that are already well-covered while ignoring areas of genuine demand.
What this solution does:
The complete content library is vectorized using transformer-based semantic embedding models representing each piece of content as a high-dimensional mathematical vector encoding its topical position in semantic space. UMAP (Uniform Manifold Approximation and Projection) reduces these high-dimensional vectors to a navigable topology that reveals the actual clustering structure of the content library.
HDBSCAN (Hierarchical Density-Based Spatial Clustering) identifies genuine topic clusters within this topology revealing over-saturated areas where multiple pieces of content occupy the same semantic territory and under-covered areas where semantic space exists without content representation.
The SERP semantic space for the target market is modeled separately identifying the full topical territory that audiences are searching within and comparing it against the content library’s current topological coverage. Gaps between SERP semantic space and content library coverage are ranked by search demand, competition level, and alignment with the site’s existing authority profile producing a mathematically prioritized content gap roadmap.
Who needs this:
Businesses with content libraries of 50 or more published pieces particularly those that have been producing content consistently for multiple years without a systematic semantic architecture review. SaaS companies with extensive educational content libraries. Media publishers and B2B businesses where organic content is a primary lead generation channel.
Solution 02 Linguistic Style & Topic Drift Analysis
Powered by Latent Dirichlet Allocation (LDA) + Temporal Semantic Shift Detection
The problem this solves:
Content libraries decay in two distinct dimensions over time and standard analytics tools detect neither with sufficient precision to prioritize remediation effectively.
Topical decay: Content that addressed a relevant audience need at the time of publication gradually becomes misaligned with how audiences currently think about and search for the same topic. The specific language used, the examples cited, the questions addressed, and the semantic territory covered drift away from the current SERP reality as the topic evolves without any visible signal on standard analytics platforms until rankings begin to decline.
Stylistic drift: In content libraries produced by multiple contributors over time, or by a single creator whose voice has evolved, individual pieces drift away from the established brand voice in tone, vocabulary, formality level, and argumentative structure. This drift is invisible to standard content auditing tools and gradually erodes the coherent brand identity that makes content libraries authoritative rather than merely informational.
Both forms of drift represent invested content production budget that is silently losing value without any mechanism for detection in standard content analytics.
What this solution does:
Latent Dirichlet Allocation (LDA) topic modeling is applied to the full content library extracting the underlying topic distributions of every piece of content and comparing those distributions against two reference points: the current SERP topic distribution for the same queries, and the brand’s established voice profile derived from the highest-performing content produced during the brand’s strongest performance periods.
Temporal Semantic Shift Detection identifies content pieces where the topic distribution has drifted most significantly from both the current SERP standard and the brand voice profile ranking drift severity mathematically and prioritizing pieces for update, consolidation, or retirement based on the combination of drift magnitude and current traffic contribution.
The measurable outcome:
A mathematically prioritized content refresh roadmap that concentrates update effort on pieces where topical and stylistic drift has created the greatest gap between current content performance and mathematical potential rather than updating content based on publication date or subjective editorial judgment.
Who needs this:
Businesses with content libraries published over multiple years, content teams with multiple contributors, and brands that have undergone positioning or tone-of-voice evolution where older content no longer represents the current brand accurately.
Solution 03 Multi-Touch Fractional Content Attribution
Powered by Markov Chain Conversion Pathing Graph Engines + Shapley Value Content Attribution
The problem this solves:
Standard content attribution assigns conversion credit to a single content touchpoint either the first content piece a customer interacted with (first-touch) or the last content piece before conversion (last-touch). Both models are mathematically indefensible for content marketing because they ignore the causal contribution of every content touchpoint that occurred between the first and the last.
The result: content pieces that assist conversions moving customers through the consideration process without being the first or last touchpoint receive no attribution credit and are systematically undervalued in budget and production decisions. Top-of-funnel educational content that initiates customer journeys appears to generate zero revenue in last-touch reports, causing it to be deprioritized or eliminated from content strategy removing the foundation of the entire content-driven conversion funnel.
What this solution does:
Customer journey data is extracted from the analytics infrastructure all content touchpoints, in order, for every customer who converted over a defined historical period. This data is structured as a directed graph where nodes represent individual content pieces and edges represent customer transitions between content pieces.
Markov Chain modeling is applied to this conversion pathing graph estimating the removal effect of each content piece (the reduction in overall conversion probability that would result if that piece were removed from the graph). Pieces with high removal effects are assigned proportionally higher attribution credit identifying the content pieces that are genuinely critical to the conversion pathway regardless of their position in the journey.
Shapley Value attribution is calculated as a complementary model applying game theory cooperative value allocation to distribute conversion credit across all content touchpoints based on each piece’s marginal contribution across all possible journey orderings.
The combination of Markov Chain removal effect analysis and Shapley Value attribution produces a multi-dimensional content attribution model that is substantially more causally defensible than any single-touch or arbitrary linear attribution approach.
Who needs this:
Businesses where content marketing is a primary inbound channel and where content investment decisions are being made based on last-touch or first-touch attribution models that systematically undervalue mid-funnel content. B2B businesses with long consideration cycles where multiple content touchpoints occur across weeks or months before conversion. SaaS companies where educational content drives trial sign-ups and where trial-to-paid conversion involves additional content engagement.
Solution 04 Content Scraping & Fingerprint Fraud Detection
Powered by Locality-Sensitive Hashing (LSH) + MinHash Shingling + Semantic Duplicate Detection
The problem this solves:
Original content particularly high-performing content that ranks well and generates significant organic traffic is a target for systematic scraping and republication. Content theft damages organic performance in two distinct ways:
Duplicate content signal dilution: When scraped content is republished on other domains sometimes within hours of original publication it creates competing duplicate content signals that can confuse Google’s duplicate content handling systems, particularly when the scraping site has higher domain authority than the original publisher.
Attribution and authority fragmentation: Original content that is scraped and republished without attribution loses the social signals, backlinks, and engagement metrics that would have accrued to the original fragmenting the authority signals that build long-term organic performance.
Standard plagiarism detection tools Copyscape, Grammarly plagiarism checker detect exact or near-exact text matches. They do not detect semantic paraphrasing (content that is rewritten to avoid exact match detection while preserving the same informational content), structural copying (using the same content architecture with different surface language), or systematic scraping patterns (automated systems that republish at scale with randomized sentence-level variations).
What this solution does:
MinHash Shingling generates compact mathematical fingerprints of every piece of original content representing the content’s unique combination of n-gram patterns as a compact hash signature. These fingerprints are indexed using Locality-Sensitive Hashing enabling efficient similarity search across the entire web at scale.
Regular web crawls compare content across known scraping sources, article aggregators, and competitor sites against the original fingerprint database identifying near-duplicate matches that evade exact-text detection through paraphrasing or structural modification.
Semantic duplicate detection using transformer-based embedding similarity identifies content that has been substantially rewritten while preserving the same informational structure capturing sophisticated scraping operations that text-fingerprinting methods miss.
Identified infringement instances are ranked by the authority level of the scraping site and the estimated organic impact prioritizing DMCA takedown actions, disavow file updates, and canonical tag enforcement based on mathematical assessment of organic performance damage.
Who needs this:
High-volume content publishers, media businesses, B2B SaaS companies with extensive educational content libraries, and any business where content production represents significant investment and where organic performance from that content is a primary revenue driver.
Solution 05 Micro-Engagement Dropout Modeling
Powered by Survival Analysis on Scroll-Depth Latency via BigQuery + Reading Behavior Reconstruction
The problem this solves:
Standard content engagement metrics time on page, bounce rate, scroll depth percentage are aggregate measures that provide insufficient precision for actionable content optimization.
Knowing that “average scroll depth is 65%” does not tell you whether the 35% of content below the fold is failing because readers completed the content and left satisfied, because the content lost their attention at a specific structural point, or because they found the information they needed early and left without needing to scroll further.
Knowing that “average time on page is 3 minutes 42 seconds” does not tell you whether readers are engaging with specific sections introductions, case studies, technical explanations, CTAs or scrolling past them. It does not tell you which structural elements cause reading velocity to slow (indicating high engagement) versus which cause it to accelerate (indicating the reader is scanning for something they are not finding).
Without this precision, content optimization is directed by editorial intuition rather than mathematical evidence of exactly where content structure is serving reader intent and where it is failing.
What this solution does:
Raw behavioral event data scroll position, scroll velocity, reading pause patterns, click behavior, and session timestamps is extracted from GA4 via BigQuery at the individual user session level. This granular behavioral data is used to reconstruct approximate reading trajectories for each page and user session.
Survival Analysis is applied to the reconstructed reading data modeling, for each position within a content piece, the “hazard” of reader dropout (the probability of the reader leaving at that specific point, conditional on having reached it). The survival function across the full length of each content piece reveals the structural dropout profile identifying specific sections, transition points, or content elements where reader engagement terminates at statistically anomalous rates.
This produces a mathematically precise map of reader dropout behavior distinguishing natural reading completion points from structural failures where content is losing reader attention. Content restructuring recommendations are prescribed based on dropout hazard analysis with each recommended change accompanied by an estimated impact on content completion rate.
Who needs this:
Businesses where content conversion rates are below industry benchmarks despite high traffic volume indicating content is attracting the right audience but losing them before they reach conversion-relevant content. Long-form content publishers where completion rate directly impacts the depth of audience relationship and downstream conversion probability. Businesses where CTA placement and content structure decisions are currently made without behavioral evidence of where readers are actually engaging versus disengaging.
How Content Marketing Intelligence Connects to the Broader Intelligence Framework
Content Marketing Intelligence does not operate in isolation. Every solution above connects to components of the broader Cognitive Marketing Engine:
Topical Saturation Mapping feeds directly into Loop 1 Empirical Diagnostics identifying the semantic structure of the content landscape before any content production or optimization decisions are made.
Fractional Content Attribution connects to Loop 2 Causal Strategy providing the mathematically validated attribution data that informs channel budget allocation decisions across the full marketing portfolio.
Micro-Engagement Dropout Modeling informs Loop 3 Programmatic Execution enabling automated content delivery optimization based on behavioral engagement signals rather than static content structures.
Drift Analysis and Fingerprint Detection connect to Loop 4 Continuous Optimization maintaining content library quality and integrity as the content ecosystem evolves over time.
Together, these solutions transform content marketing from a production activity into a mathematically optimized revenue generation system with every production, optimization, and distribution decision backed by causal evidence rather than editorial intuition.
The Honest Answers to Real Client Questions
“We already track content performance in Google Analytics. Why is this different?”
Google Analytics provides descriptive aggregate metrics what happened at the surface level. Content Marketing Intelligence operates on raw behavioral event data extracted from GA4 via BigQuery reconstructing individual-level reading behavior, modeling causal content attribution, and applying mathematical models that generate predictive and prescriptive outputs rather than descriptive summaries. The question is not whether you are tracking content. The question is whether you are extracting the causal intelligence from that tracking data that is necessary to make mathematically defensible content investment decisions.
“Our content consistently ranks well. Do we still need saturation mapping?”
Well-ranking content in an over-saturated topical area is operating below its mathematical potential because organic authority is being split across multiple pieces competing for the same intent rather than concentrated in a single authoritative piece. Saturation mapping is most valuable precisely when content is performing adequately because it identifies the optimization opportunity that exists between current performance and the higher performance achievable through consolidation and semantic architecture improvement.
“Content attribution has always been difficult. Is there really a better model than last-touch?”
Last-touch attribution is not a neutral choice it is a systematically biased model that consistently undervalues top-of-funnel and mid-funnel content while overcrediting bottom-of-funnel content and paid channels. Markov Chain and Shapley Value attribution are not perfect models no attribution model is but they are mathematically more defensible than last-touch because they account for the causal contribution of every touchpoint in the conversion journey rather than arbitrarily crediting only the final one.
“Can you guarantee improved content performance from these solutions?”
No specific performance metric guarantee is made. What is guaranteed: mathematically precise identification of the specific structural, topical, and attribution-related problems limiting current content performance with statistical evidence of the magnitude of each problem before any intervention is implemented.
Who Content Marketing Intelligence Is Built For
B2B SaaS and technology companies where educational content is the primary inbound channel and where content investment decisions are made without mathematically validated attribution evidence.
Media publishers and content-first businesses with large content libraries where topical saturation, content decay, and scraping fraud are ongoing structural challenges.
Enterprise marketing teams where content production budgets are significant and where CFO-level justification of content investment requires causal attribution evidence beyond assisted conversion reports.
Ecommerce brands with substantial editorial content programs where the relationship between content engagement and purchase conversion involves multiple touchpoints across extended consideration cycles.
Agencies managing content marketing for clients who need to prove incremental content value with mathematical rigor and who need to optimize content production allocation based on causal attribution rather than last-touch metrics.
The diagnosis starts with your content data not your editorial calendar.
→ Start With the Audit (link to /work-with-me)
→ Understand the Framework (link to /approach/my-framework)
→ View All Solutions (link to /solutions)